업무 관련으로 사내 적용을 위한 디렉토리 구성안이며,
디렉토리 용량 등은 임의로 지정된 부분임을 언급합니다.
설치/구성 (no script)
서버 구성
| 구분 | 버전 | 비고 |
| 환경 | cloud VM 환경 또는 vmware/oracle vm을 통한 가상vm 환경 서버 - Version : Rocky 8 (release 8.9) |
2node 테스트 시에는 oracle vm으로, 3node 테스트 시에는 GCP에서 서버 구성. OS 선택 시 Linux 계열로 진행 하였고, 2node : centos 7, 3node : Rocky 8 로 수행 |
| 리소스 | - 리소스 사양 : 4C 4G - 서버 대수 : 3EA |
아래 kafka와 zookeeper의 기본 heap memory를 참고해서 서버 메모리는 조정하면 된다. cloud 서비스를 이용한다면 각 리소스 제공 표에 따라 4C 4G 이상으로 진행 하면 좋다. [ heap memory default setting ] - kafka : 1G (~bin/kafka-server-start.sh) - zookeeper : 512M (~bin/zookeeper-server-start.sh) |
| Disk 구성 | [ os ] / : 30G # os 영역 [kafka] /kafka 10G #엔진 영역 /kaf_data 20G #데이터 영역 /zoo_data 20G #데이터 영역 /svc_log 20G #서비스 로그 영역 |
os 영역은 현재 테스트 서버 만드는 형상 관련이니 참고만 한다. kafka 용도를 위해 디스크를 별도 추가 할당 하여 구성 한다. 서버 생성 후 바로 디스크 세팅 해주면 되고 파일시스템은 centos7, rocky8 둘다 xfs 로 구성/포맷 했다. # cd / # mkdir kafka kaf_data zoo_data svc_log 그 다음 mount 처리 후 fstab에 마운트 포인트별로 등록한다. 별도의 디스크를 할당 받지 않고 / 이하에 그냥 생성했을 경우 fstab 작업 불필요 |
| kafka | kafka_2.13-3.7.0 로 진행 한다. | Released Feb 27, 2024 |
kafka 구성
| # | 내용 | 명령어 |
| 계정 root 로 작업 수행 | ||
| 1 | yum으로 필요한 프로그램들을 설치 한다. ** java는 openjdk 11로 설치 *** 오른쪽 내용 중에 서버에 이미 설치 되어 있는 파일이 있을 수도 있음. |
# yum install java-11-openjdk.x86_64 -y # yum install vim-common.x86_64 -y # yum install binutils.x86_64 -y # yum install lsof -y # yum install nmap-ncat.x86_64 –y # yum install wget.x86_64 –y # yum install java-11-openjdk-devel.x86_64 -y (produce/consume 테스트 관련으로 javac 필요하여 설치) |
| 2 | /etc/hosts파일에 broker 서버 호스트명과 ip 매칭해주기 (이하 호스트명은 broker1, broker2, broker3 임) 모든 서버의 /etc/hosts에 작업 필요. 단, GCP, AWS 등 외부 IP가 있다면 입력 시 해당 서버의 broker는 내부 IP로, 연동 서버는 외부 IP로 입력해준다. |
<< 예시 >> 호스트 내부 ip 외부ip broker1 10.123.123.123 35.123.123.123 broker2 10.123.123.124 35.123.123.124 broker3 10.123.123.125 35.123.123.125 ex) broker1번 수정 작업 시 ## root 수행 # cp -a /etc/hosts /etc/hosts_orig # vi /etc/hosts 10.123.123.123 broker1 ##10.x.x.x 내부 ip 35.123.123.124 broker2 ## 외부 ip 35.123.123.125 broker3 ## 외부 ip |
| 3 | kafka 솔루션 계정 생성 | # useradd kafka ** 별도의 관리그룹이 있거나 한다면 옵션값 주면 됨. # passws kafka |
| 4 | kafka 계정의 .bash_profile에 JAVJA_HOME jdk 위치 잡아주기 (export~) |
# su - kafka ##계정이 kafka가 아닌경우 # cd ~kafka # vi .bash_profile #####아래 확인/추가###### export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.22.0.7-2-.el8.x86_64 export PATH=$PATH:$JAVA_HOME/bin *** 경로는 서버의 ls로 확인해서 복붙하는게 정확 |
| 5 | 서버 구성 시 포맷 및 mount 한 디렉토리에 대해 아래 depth로 디렉토리를 생성한다. /kafka/app/configuration /kafka/app/script /kafka/app/src /zoo_data/translog /svc_log/kaf_log /svc_log/zoo_log 그리고 디렉토리에 대해 전부 kafka 계정 권한을 부여한다. |
# mkdir /kafka/app/configuration /kafka/app/script /kafka/app/src # mkdir /zoo_data/translog /svc_log/kaf_log /svc_log/zoo_log 디렉토리 권한은 아래와 같이 준다. (디렉토리 나열해서 되는진 안해봄ㅋㅋㅋ) # chown kafka:kafka -R /kafka # chown kafka:kafka -R /kaf_data # chown kafka:kafka -R /zoo_data # chown kafka:kafka -R /svc_log |
| 이 시점부터 kafka 계정으로 진행합니다. root로 되어있는 파일이나 디렉토리가 있는경우 chown -R kafka:kafka 디렉토리명 또는 파일명을 적어서 kafka 권한으로 변경합니다. |
||
| 6 | kafka_2.13-3.7.0.tgz (binary file, scala 2.13) /kafka/app/src로 파일 다운로드 및 /kafka에 압축 해제 |
# wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz # tar -zxvf kafka_2.13-3.7.0.tgz -C /kafka |
| 7 | /kafka/kafka_2.13-3.7.0/config 에서 server.properties, zookeeper.properties 2파일 /kafka/app/configuration 복사 /kafka/app/configuration 에서 원본파일용으로 한번 더 복사 |
# cp /kafka/kafka_2.13-3.7.0/config/server.properties /kafka/app/configuration # cp /kafka/kafka_2.13-3.7.0/config/zookeeper.properties /kafka/app/configuration # cd /kafka/app/configuration # cp -a server.properties server.properties_org # cp -a zookeeper.properties zookeeper.properties_org |
| 8 | /kafka/app/configuration의 server.properties와 zookeeper.properties 파일 수정 |
[ kafka - server.properties ] ## 주석 해제 및 수정 - listeners=PLAINTEXT://:9092 - advertised.listeners=PLAINTEXT://hostname:9092 ## 내용 수정 - broker.id=1 or 2 or 3 ###이거 서버별로 설정하는거임. - log.dirs=/kaf_data - offsets.topic.replication.factor=3 - zookeeper.connector~ /zoo_data ## 추가 config - min.insync.replicas=2 [ zookeeper - zookeeper.properties ] ## 내용 수정 - dataDir=/zoo_data (snapshot) ## 추가 config - dataLogDir=/zoo_data/translog - tickTime=2000 - initLimit=10 - syncLimit=5 - server.1=broker1:2888:3888 - server.2=broker2:2888:3888 - server.3=broker3:2888:3888 |
| 9 | /kafka/kafka_2.13-3.7.0/bin dir의 heap mem 수정해주기 (서버에 맞게) export 해서 변경할 수 있으면 그렇게 변경해도 될 것 같으나 방법을 모르겠음..ㅋㅋ;; |
kafka-server-start.sh : KAFKA_HEAP_OPTS :: default 1G zookeeper-server-start.sh : KAFKA_HEAP_OPTS :: default 512m |
| 10 | /zoo_data 에 broker별로 myid 1,2,3 생성 |
broker1 서버 # cd /zoo_date # echo 1 >> myid broker2 서버 # cd /zoo_date # echo 2 >> myid broker3 서버 # cd /zoo_data # echo 3 >> myid |
| 11 | 서비스 기동 zookeeper -> kafka 순으로 기동하고, kafka -> zookeeper 순으로 서비스를 내린다. 기동 명령어는 LOG_DIR 값을 export 해서 쓰지않고 명령어 라인으로 한줄에 넣는걸로 했다. (사내에서는 간단하게 start, stop script로 해놔서 긴 줄 안쓰게 했다.) LOG_DIR 값을 주지 않고 기동할 경우, 아래 "디렉토리 구성안" 의 AS-IS 형상에서 kafka~/logs 로 파일이 생기게 되므로, 상황에 따라서 설정 하면 되겠다. |
zookeeper 기동 #LOG_DIR=/svc_log/zoo_log /kafka/kafka_2.13-3.7.0/bin/zookeeper-server-start.sh -daemon /kafka/app/configuration/zookeeper.properties kafka 기동 # LOG_DIR=/svc_log/kaf_log /kafka/kafka_2.13-3.7.0/bin/kafka-server-start.sh -daemon /kafka/app/configuration/server.properties /////// 중단 /////// 그냥 bin dir가서 kafka부터 내리면 되는데, kafka가 내려가는데 시간이 좀 걸린다. 따라서 kafka가 내려간거 꼭 확인 한 다음 zookeeper를 내리는게 좋다. (성질급해서 막 내렸다가 kafka 를 kill로 죽여야 할수 있다.) 대충 bin으로 가서 # ./kafka-server-stop.sh # ./zookeeper-servere-stop.sh |
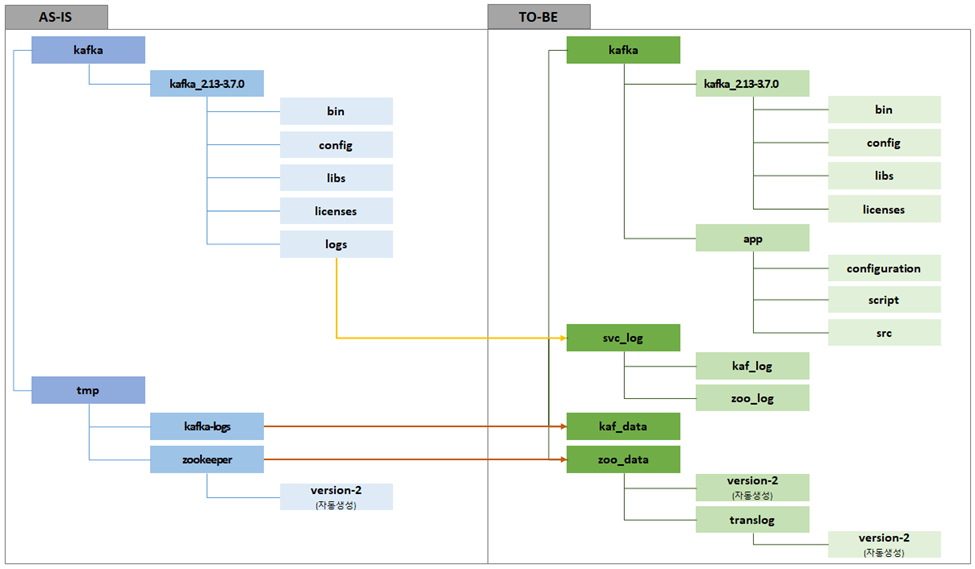
디렉토리 구성안에 대한 원본/변경안 내역
data영역은 properties에서 변경할 수 있고,
솔루션 로그는 kafka-run-class.sh 에서 사용하는 LOG_DIR 을 통해 핸들링할 수 있다.
kafka-run-class.sh는 kafka의 bin DIR에 거의 모든 *.sh 파일에 들어있는데,
우리가 실질적으로 기동할 때 쓰는 형상의 스크립트 (ex, kafka-server-strat, zookeeper-server-start) 에서의 export 형식으로 값을 줘서 사용 해주거나 어딘가의 파일에 export 해서 사용하면 된다.
(위 11번 항목 참고)
첨에는 log를 다 쪼갰는데, mount point가 너무 많다는 지적으로 log를 줄였다.
data까지 줄이면 어떠냐는 질문에는 zoo_data의 snapshot 데이터의 약간의 복구 형상 관련으로 disk가 분리되는게 안전할것 같다 말하며 방어했다.
zoo_data의 snapshot 의 복구 기능은 사실 partition(kaf_data)의 껍데기 형상만의 복구지만,
아무것도 복구 안되는 것보단 낫긴하지만은 사실 프로세스가 다 내려간 상태에서는 전체 초기화가 될 수 있으므로 사실 좀 위험하기도 하다.
snapshot으로 여러번 테스트 했지만 복구는 역시 mirror-maker를 통해서 복구하는게 맞아보인다.
###mirror-maker는 아직 테스트를 하지 못했다..
 |
'업무 > kafka zookeeper' 카테고리의 다른 글
| [etc] Kafdrop (0) | 2024.07.16 |
|---|---|
| [kafka][zookeeper] min.insync.replicas (0) | 2024.04.02 |
| [zookeeper] snapshot data(version-2) 정리 (update 240402) (0) | 2024.03.21 |
| [zookeeper] port 접속 현황 이게 맞는거임...? (0) | 2024.03.07 |
| [GCP][kafka][zookeeper] clustering test (0) | 2024.02.23 |